DeepSeek's surprisingly inexpensive AI model challenges industry giants. The company claims to have trained its powerful DeepSeek V3 neural network for a mere $6 million, utilizing only 2048 GPUs, a stark contrast to competitors' expenses. However, this figure is misleading.
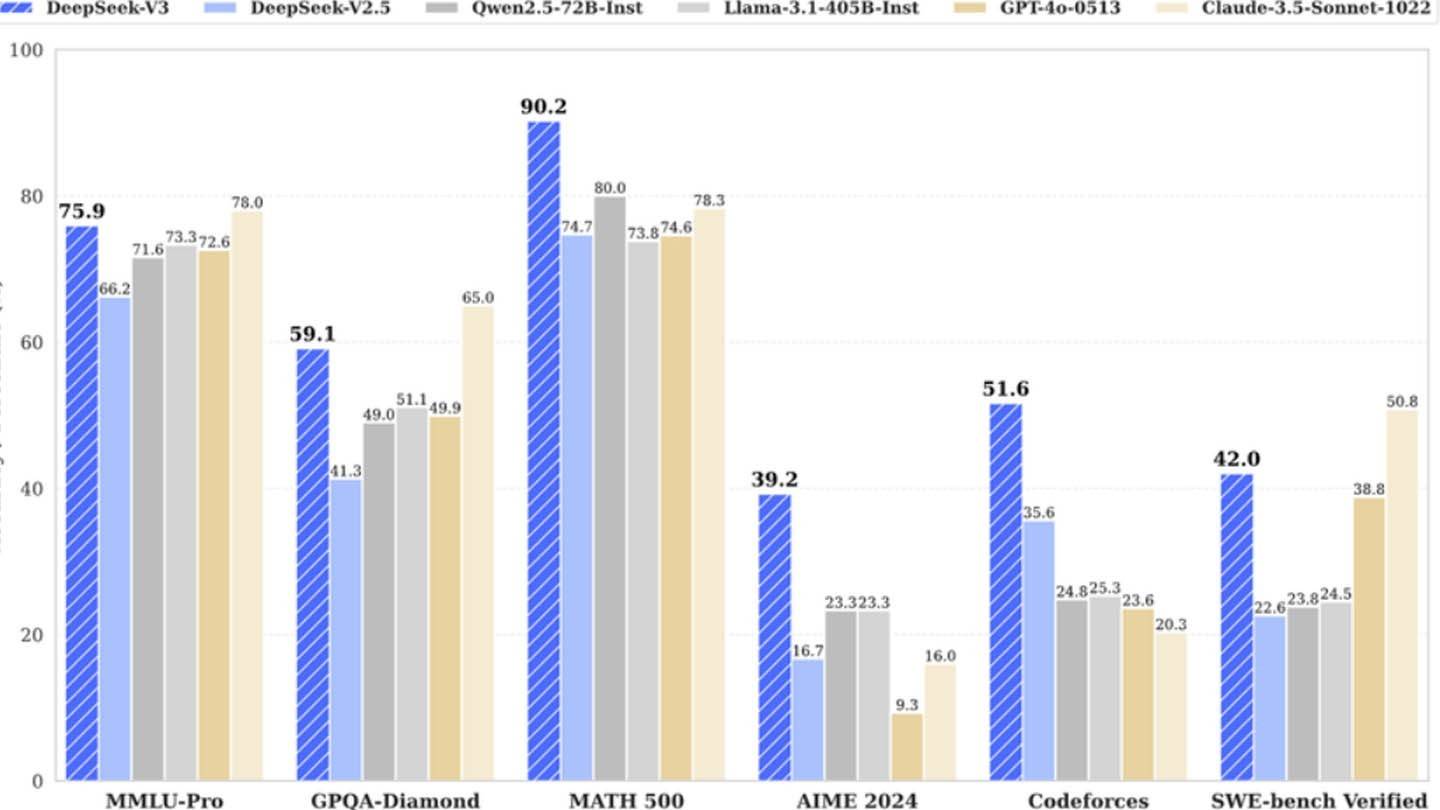 Image: ensigame.com
Image: ensigame.com
DeepSeek V3's innovative architecture contributes to its efficiency. Key technologies include Multi-token Prediction (MTP), which predicts multiple words simultaneously; Mixture of Experts (MoE), employing 256 neural networks for enhanced processing; and Multi-head Latent Attention (MLA), focusing on crucial sentence elements for improved accuracy.
 Image: ensigame.com
Image: ensigame.com
Contrary to its publicized cost, SemiAnalysis reveals DeepSeek operates a massive infrastructure of approximately 50,000 Nvidia GPUs, valued at roughly $1.6 billion, with operational costs nearing $944 million. This substantial investment, coupled with high salaries for its researchers (exceeding $1.3 million annually), significantly surpasses the initial $6 million claim.
 Image: ensigame.com
Image: ensigame.com
DeepSeek's success stems from its unique structure: a subsidiary of High-Flyer, a Chinese hedge fund, it owns its data centers, fostering rapid innovation and optimization. Its self-funded nature enhances agility. While the "budget-friendly" narrative is exaggerated, DeepSeek's overall investment exceeding $500 million still represents a comparatively lean approach.
 Image: ensigame.com
Image: ensigame.com
The contrast to competitors is striking. DeepSeek's R1 model cost $5 million, compared to ChatGPT4o's $100 million. DeepSeek's example showcases a path to competitiveness, but its success is undeniably rooted in substantial investment and technological advancements, not solely its purportedly low training costs. Despite the inflated claim, it still undercuts competitors significantly.





